
Ok, this will be another nerdy post, thinking out loud about my explorations of evolutionary algorithms and Kauffman-inspired networks of pixels.
I have been doing plenty of experiments, at first tweaking the ways I do selection and mutation. I get the best results using some kind of annealing: I am decreasing the size and frequency of mutations during the run. In this way it explores a larger territory in the beginning and doesn’t get knocked off fitness peaks higher on. Also I am using a weird selection scheme I (re-?)invented: I use linear ranking and stochastic universal sampling, but as the run progresses I increase the ‘elitism’. It starts with an elitism of one, and at the end of the run what happens boils down to truncation. This gives the best results I’ve had so far; it makes sure that the population doesn’t converge too quickly (which is the problem of truncation) and it also makes sure lucky accidents are kept (which is frustrating about stochastic universal sampling). I am very much aware that I am half-informed, that there is a whole field of theory here and that I’m probably mixing things up terribly, but it works, and at this time I’d rather do something than read general books in preparation…
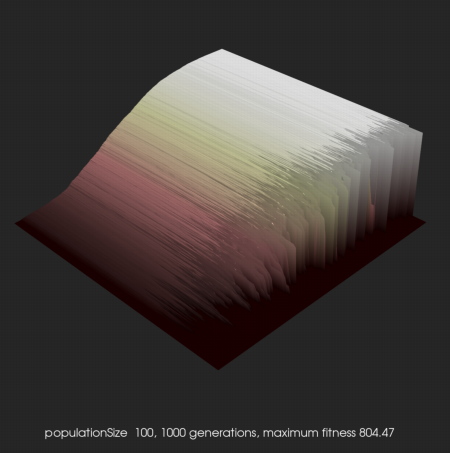
Related to this I’ve been thinking about the carpet-plots I make of my evolution runs and what they say about the shape of the fitness-landscape. The first plot above looks very healthy. The second plot, just below here, is of an unfinished run using the same scheme but on a much bigger network. It shows that most mutants are much less fit, so the fitness peaks must be a lot steeper. The third plot shows a run of a much bigger network, starting from a tiling of a small network with high fitness. It shows that there is hardly any improvement during the run, but I don’t understand why the mutants still look relatively fit too. And the last plot is great: i’ve started trying things with networks that are much more sparse and the results are weird. It looks as if it is ascending a steep and isolated peak, and both runs I’ve done so far show the same plateau at the end of the run. The fittest results are creepy-looking, small networks living in a total void of disconnected, ‘dead’ pixels.
And just at the moment I was starting to wonder how to scale my experiments to much larger networks, Jelle Feringa pointed me to the great writings of Greg Hornby, who I only knew from his evolved antenna project. I’ve been reading some papers by Peter Bentley before about the same topic, so I was thinking of evolving a ‘weaver’ of networks rather than the networks themselves. Hornby is very precise about what ‘generative representations’ are, so that is great. Some of his recent papers are great introductions, but he most detailed source of information still is his PhD thesis.
Thanks Jelle !


